ในยุคที่ “ข้อมูล” ถูกเปรียบเปรยว่าเป็นน้ำมันดิบแห่งศตวรรษที่ 21 ประเทศไทยถือเป็นหนึ่งในประเทศที่มี “บ่อน้ำมัน” ขนาดใหญ่และทรงคุณค่าที่สุดแห่งหนึ่งในโลก นั่นคือ ฐานข้อมูลด้านสาธารณสุข
ด้วยโครงสร้างระบบสุขภาพของไทยที่ครอบคลุมประชากรเกือบ 100% ผ่าน 3 กองทุนหลัก ได้แก่ สำนักงานหลักประกันสุขภาพแห่งชาติ (สปสช. หรือ บัตรทอง), สำนักงานประกันสังคม (สปส.), และ กรมบัญชีกลาง (สวัสดิการข้าราชการ) หน่วยงานเหล่านี้ไม่ได้ทำหน้าที่เพียงแค่ผู้จ่ายเงิน (Payer) แต่คือผู้ถือครองข้อมูลขนาดใหญ่ (Big Data) ที่บันทึกประวัติการรักษา การใช้ยา และค่าใช้จ่ายของคนไทยทั้งประเทศ
อย่างไรก็ตาม ปัญหาคอขวดสำคัญคือการเข้าถึงและการนำข้อมูลเหล่านี้ออกมาใช้ประโยชน์ (Data Utilization) เพื่อการวิจัยและการวางแผนเชิงนโยบายยังคงทำได้ยาก หรือกระจายตัวอยู่ บทความนี้จึงขอเสนอแนวทางนโยบายสาธารณะว่าด้วย “การเปิดเผยและแลกเปลี่ยนข้อมูลสุขภาพ (Health Data Sharing Policy)” ผ่านโมเดลการจัดลำดับชั้นข้อมูล 3 ระดับ เพื่อสร้างสมดุลระหว่างการใช้ประโยชน์และการคุ้มครองข้อมูลส่วนบุคคล
ฐานข้อมูลสุขภาพ: กระจกสะท้อนปัญหาระดับชาติ
ข้อมูลการเบิกจ่าย (Claims Data) จาก 3 กองทุนหลัก คือจิ๊กซอว์ชิ้นสำคัญ ข้อมูลเหล่านี้มีความละเอียดระดับรายธุรกรรม (Transaction) ซึ่งหากนำมาวิเคราะห์ จะทำให้เราเห็นภาพรวมที่ชัดเจนอย่างที่ไม่เคยมีมาก่อน อาทิ:
- สถานะสุขภาพ: ความเจ็บป่วย ความรุนแรง ความถี่ และอุบัติการณ์ของโรคในแต่ละพื้นที่
- ประสิทธิภาพการรักษา: ชนิดและปริมาณยาที่สั่งจ่าย อุปกรณ์ทางการแพทย์ที่ใช้ ระยะเวลาในการรักษา
- มิติทางเศรษฐศาสตร์: ต้นทุนค่ารักษาพยาบาล การกระจายตัวของทรัพยากร
- มิติทางสังคม: ความสัมพันธ์ระหว่างโรคกับ อาชีพ อายุ เพศ และถิ่นที่อยู่
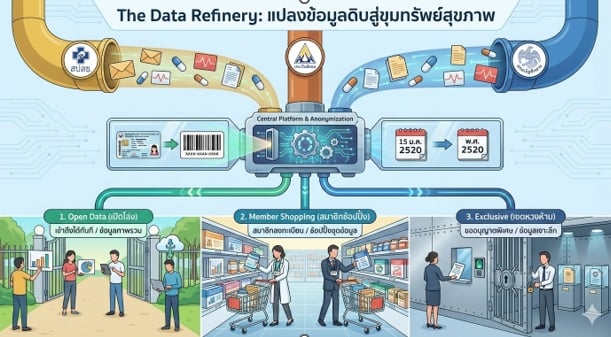
เพื่อปลดล็อกข้อมูลเหล่านี้มาใช้ประโยชน์อย่างเป็นระบบ รัฐควรผลักดันนโยบายการจัดชั้นข้อมูล (Data Classification) และการเข้าถึงเป็น 3 ระดับ ดังนี้:
ข้อเสนอ: การจัดระดับการเข้าถึงข้อมูล 3 ระดับ (The 3-Tier Access Model)
นโยบายสาธารณะควรระบุให้มีการสร้าง Platform กลาง ในการเชื่อมโยงข้อมูล แต่แบ่งสิทธิ์การเข้าถึงตามความละเอียดและความอ่อนไหวของข้อมูล:
1. ระดับเปิดสาธารณะ (Open Data)
นี่คือระดับพื้นฐานที่ บุคคลทั่วไป สามารถเข้าถึงและดาวน์โหลดไปใช้งานได้ทันที (Machine-readable format) ข้อมูลในระดับนี้ควรเป็นข้อมูลภาพรวม ข้อมูลสถิติ หรือข้อมูลที่ผ่านการสังเคราะห์แล้ว ไม่สามารถระบุตัวตนบุคคลได้ (Aggregated Data) เหมาะสำหรับการนำไปทำ Dashboard หรือรายงานสถานการณ์ทั่วไป
2. ระดับสมาชิก (Member / Registered Users)
คือระดับ “กึ่งเปิด” สำหรับกลุ่มนักวิจัย นักวิชาการ หรือหน่วยงานวางแผนที่ลงทะเบียนยืนยันตัวตนชัดเจน (KYC) บนแพลตฟอร์ม
- รูปแบบ: เป็นลักษณะ “Data Shopping” คือมีชุดข้อมูล (Datasets) ที่เตรียมไว้แล้ว (Pre-processed) วางอยู่บนชั้นวาง สมาชิกสามารถเลือกหยิบไปใช้ได้ทันทีโดยไม่ต้องทำเรื่องร้องขอเป็นรายครั้ง
- ลักษณะข้อมูล: มีความละเอียดมากขึ้น อาจแยกเป็นรายพื้นที่ หรือรายกลุ่มโรค แต่ยังคงมีการจัดการเพื่อปกปิดตัวตนอย่างเคร่งครัด
3. ระดับร้องขอเป็นการเฉพาะ (Exclusive)
คือระดับที่มีความละเอียดสูงสุด เหมาะสำหรับงานวิจัยเชิงลึกที่ต้องการข้อมูลจำเพาะเจาะจง
- กระบวนการ: ต้องทำการร้องขอผ่าน Platform กลาง โดยระบุวัตถุประสงค์โครงการวิจัยที่ชัดเจน และต้องผ่านการอนุมัติจากคณะกรรมการจริยธรรมหรือหน่วยงานเจ้าของข้อมูล (Data Owner) ก่อนส่งต่อข้อมูล
- ลักษณะข้อมูล: ข้อมูลรายบุคคลที่มีความละเอียดสูง (Microdata) ที่จำเป็นต้องควบคุมการใช้งานอย่างเข้มงวด
หัวใจสำคัญ: การปกปิดตัวตน (De-identification) กับความละเอียดข้อมูล
ประเด็นที่ท้าทายที่สุดของนโยบายนี้คือ การทำให้ข้อมูลทั้ง 3 ระดับ (โดยเฉพาะระดับ 2 และ 3) ยังคงรายละเอียดในระดับ Transaction รายบุคคล เพื่อให้ประมวลผลได้แม่นยำ แต่ต้องไม่ละเมิดสิทธิส่วนบุคคล
นโยบายต้องกำหนดมาตรฐานการตัดทอนข้อมูลจี้จำเพาะบุคคลและลดทอนความละเอียดข้อมูลที่ชัดเจน เช่น:
- ตัดข้อมูลระบุตัวตนโดยตรง เช่น ชื่อ-นามสกุล, เลขบัตรประชาชน, ที่อยู่บ้านเลขที่ ต้องถูกนำออกทั้งหมด
- ลดความละเอียดข้อมูล (Generalization):
- วันเดือนปีเกิด: ให้ปรับเหลือเพียง “ปีเกิด” เพื่อให้ยังสามารถคำนวณอายุของผู้ป่วยได้ ซึ่งจำเป็นต่อการวิจัย แต่ไม่เจาะจงพอที่จะระบุตัวตน
- ที่อยู่: อาจแสดงเพียงระดับตำบล หรือ อำเภอ ตามความเหมาะสมของระดับการเข้าถึง
- การสร้างรหัสสมมติ (Pseudonymization): ในกรณีที่นักวิจัยต้องการติดตามประวัติการรักษาต่อเนื่อง (Longitudinal Study) ของคนเดิมๆ ว่าไปรักษาที่ไหนบ้าง ให้ใช้วิธีสร้าง “Dummy ID” หรือรหัสสมมติขึ้นมาแทนเลขบัตรประชาชน เพื่อให้ระบบคอมพิวเตอร์แยกแยะได้ว่าเป็น “นาย ก.” คนเดิม แต่ผู้วิจัยจะไม่ทราบว่า นาย ก. คือใครในโลกความเป็นจริง
ถ้าทำได้จริง… เราจะได้อะไร?
เมื่อข้อมูลจากการเบิกจ่าย (Claim Data) ของทั้ง 3 กองทุนถูกนำมาใช้ประโยชน์ ขั้นต้นเลยเราจะเห็น “ความจริง” ที่ซ่อนอยู่ นำไปสู่การค้นใหม่ ๆ หลายอย่างเช่น:
- รู้ทันโรค: เรารู้ว่าโรคอะไรกำลังระบาดที่ไหน รุนแรงแค่ไหน
- รู้การใช้ยา: หมอสั่งยาอะไรบ้าง ปริมาณเท่าไหร่ มีการใช้ยาเกินจำเป็นไหม หรือยาตัวไหนกำลังจะขาดตลาด
- รู้พฤติกรรม: คนอาชีพไหนป่วยเป็นอะไร คนภาคไหนเสี่ยงโรคอะไร
- รู้งบประมาณ: รัฐจะรู้ว่าต้องเอาเงินไปลงที่โรงพยาบาลไหน ถึงจะคุ้มค่าและเกิดประโยชน์สูงสุด
บทสรุป: ยิ่งละเอียด ยิ่งต้องควบคุม
หลักการสำคัญของนโยบายสาธารณะฉบับนี้คือ “ความแปรผกผันระหว่างความละเอียดและการเข้าถึง”
- หากต้องการข้อมูลที่ละเอียดมาก (เช่น พฤติกรรมการใช้ยาอย่างละเอียด, เส้นทางการรักษาข้ามโรงพยาบาล) ข้อมูลนั้นจะถูกจัดอยู่ใน ระดับ 3 ซึ่งต้องมีการขออนุญาต
- หากต้องการข้อมูลเพื่อดูแนวโน้มภาพรวม ข้อมูลจะอยู่ใน ระดับ 1 หรือ 2 ที่เข้าถึงได้ง่ายกว่า
การผลักดันให้ สปสช., ประกันสังคม และ กรมบัญชีกลาง บูรณาการข้อมูลภายใต้มาตรฐานเดียวกันนี้ จะก่อให้เกิดประโยชน์มหาศาล ไม่ใช่เพียงแค่ลดความซ้ำซ้อนของการเบิกจ่าย แต่คือการสร้าง “ระบบนิเวศข้อมูลสุขภาพ” ที่ทำให้นักวิจัยและผู้วางนโยบายมองเห็นปัญหาที่แท้จริง นำไปสู่การจัดสรรงบประมาณที่ตรงจุด การมียาและเวชภัณฑ์ที่เพียงพอ และท้ายที่สุด คือระบบสาธารณสุขไทยที่เข้มแข็งและยั่งยืนบนพื้นฐานของข้อมูลจริง (Evidence-based Policy)
มนต์ศักดิ์ โซ่เจริญธรรม
นักคิดนักวิเคราะห์เพื่อประโยชน์สาธารณะ


ข่าวที่เกี่ยวข้อง
BDI ปลุกพลังผู้ประกอบการไทยใช้ Big Data และ AI ขับเคลื่อนธุรกิจ ผ่านโครงการ Connect the Dots 2025
สถาบันข้อมูลขนาดใหญ่ (องค์การมหาชน) หรือ BDI เดินหน้าเสริมพลังให้ผู้ประกอบการไทยให้ใช้ข้อมูลและปัญญาประดิษฐ์ (AI) สร้างคุณค่าใหม่ให้ธุรกิจผ่านโครงการ
มช. นำ Big Data พัฒนาแพลตฟอร์มดิจิทัลด้านพลังงานและสิ่งแวดล้อม ร่วมบูรณาการ ลดปล่อยก๊าซเรือนกระจกของประเทศไทย
มหาวิทยาลัยเชียงใหม่ ร่วมลงนามบันทึกข้อตกลงความร่วมมือ (MoU) ภายใต้ โครงการศึกษาและพัฒนาแนวทางการเก็บข้อมูลการปล่อยก๊าซเรือนกระจกภาคพลังงานในภาคอุตสาหกรรมและภาคบริการของประเทศไทย
นโยบายและกฎหมายรัฐบาลดิจิทัล (ตอนที่ 1) : งานหลังบ้านที่ถูกมองข้าม
ในปี 2562 และ 2565 รัฐบาลได้ออกกฎหมายสำคัญเกี่ยวกับความเป็นรัฐบาลดิจิทัล 2 ฉบับ คือ พระราชบัญญัติการบริหารงานและให้บริการภาครัฐผ่านระบบดิจิทัล (พ.ศ. 2562) และ พระราชบัญญัติการปฏิบัติราชการทางอิเล็กทรอนิกส์ (พ.ศ. 2565) กฎหมายทั้ง 2 ฉบับถูกออกแบบมาโดยเจตนาเพื่อให้กระตุ้นให้เกิดความเป็นรัฐบาลดิจิทัลอย่างยิ่งยวด
กรอบการพัฒนา AI Roadmap ขององค์กร
ในยุคที่ AI เป็นประเด็นสุดร้อนแรงในทุกวงการ องค์กรต้องการได้ชื่อว่าได้ นำ AI มาใช้งานแล้ว เพื่อสร้างภาพลักษณ์ความทันสมัย และ มีประสิทธิภาพ มีความพยายามส่งคนไปอบรมใช้งาน Chatbot เพื่อช่วยทำงานด้านการตลาด การใช้วาดรูป วาดกราฟ หรือ ช่วยจัดทำเอกสารวิเคราะห์รายงานต่าง ๆ
ดีอี-BDI เดินหน้าผลักดันการใช้ Big Data และ AI สู่ Data-Driven Nation ตั้งเป้าปี 67 สร้างมูลค่าทางเศรษฐกิจกว่า 3,000 ล้านบาท
กรุงเทพฯ 21 กุมภาพันธ์ 2567- กระทรวงดีอี – BDI แถลงบทบาทใหม่ เดินหน้าหนุนใช้ Big Data และ AI ขับเคลื่อนเศรษฐกิจและสังคมยุคดิจิทัล
เปิดเผยข้อมูลด้วยไฟล์คอมพิวเตอร์ Word/Excel การปรับเปลี่ยนเล็ก ๆ ที่ส่งผลใหญ่
โปรแกรม Microsoft Word/Excel เป็นโปรแกรมอยู่คู่งานภาครัฐไทยมาอย่างยาวนาน เพราะภาครัฐโดยธรรมชาติมักเต็มไปด้วยงานเอกสาร ตั้งแต่ งบประมาณ เอกสารจัดซื้อจัดจ้าง เอกสารรับรอง ใบอนุญาตต่าง ๆ